As our last post demonstrated using a classic example.
This question becomes even more important when it comes to AI-generated tests.
Many IT teams are hoping that AI will ease their testing workload. Understandable. When manual test ideas are quickly turned into automated tests, it saves time.
But the situation won’t improve just because more tests come back negative.
Relief comes when the right risks become apparent.
For example:
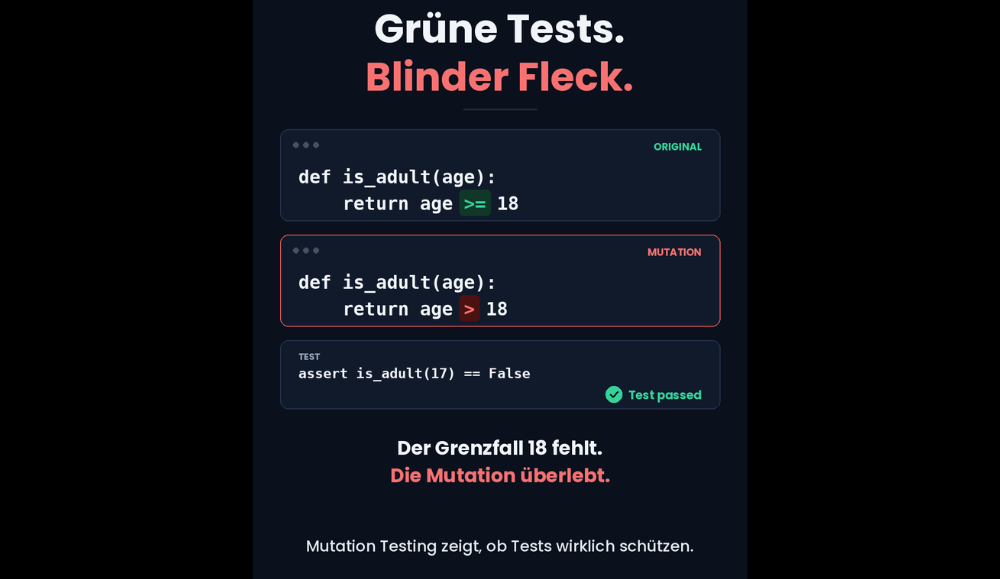
A manual test case is:
“The project manager can open the report.”
The AI uses this to generate an automated test. The test logs in the project manager, opens the report, and checks whether the expected page is displayed.
Everything is green.
Taken on its own, that’s helpful.
But that’s not enough to take on project responsibility.
Because the real questions are:
Can a regular user open the report as well?
Can a user from another team access it via a direct link?
Are old sessions actually being rejected?
Have role changes and special privileges been properly taken into account?
These aren’t just technical quibbles.
These are exactly the cases that end up causing problems later on if they slip through the cracks.
That is why AI in testing is not just a matter of automation.
It is also a matter of governance.
Anyone who wants to make effective use of AI-generated tests cannot do so without a solid professional judgment.
Teams need clearer expectations:
Which rule should be enforced?
Which counterexamples are bound to fail?
What testing conditions in the test code inspire confidence?
Who determines whether the test is valid?
At AVABIS, we don’t view these questions as a tool project, but rather as a technical assessment: What does a test really tell us, and what risks remain even if the result is positive?
The crucial question, therefore, is not:
“How quickly can we automate testing?”
Rather:
“Would these tests also turn red if there were a significant technical error in the system?”